法国大型语言模型(LLM)开发商Mistral近日推出了一款新的API——Mistral OCR,旨在帮助开发人员处理复杂的PDF文档。该API通过光学字符识别(OCR)技术,将PDF文件转换为文本文件,并以Markdown格式输出,便于AI模型摄取和处理。
与大多数OCR API不同,Mistral OCR是一款多模态API,能够检测PDF中的插图和照片,并在输出中为这些图形元素创建边界框。此外,Mistral OCR的输出采用Markdown格式,这是一种开发人员常用的格式语法,用于向纯文本文件添加链接、标题和其他格式元素。
Mistral联合创始人兼首席科学官Guillaume Lample表示:“多年来,组织积累了大量的PDF或幻灯片格式文档,这些文档通常无法被LLM(尤其是RAG系统)访问。通过Mistral OCR,我们的客户现在可以将复杂文档转换为所有语言的可读内容。这是在需要简化对其大量内部文档访问的公司中广泛采用AI助手的关键一步。”
Mistral OCR可在Mistral的API平台上使用,也支持通过AWS、Azure、Google Cloud Vertex等云合作伙伴访问。对于处理机密或敏感数据的公司,Mistral还提供本地部署选项。
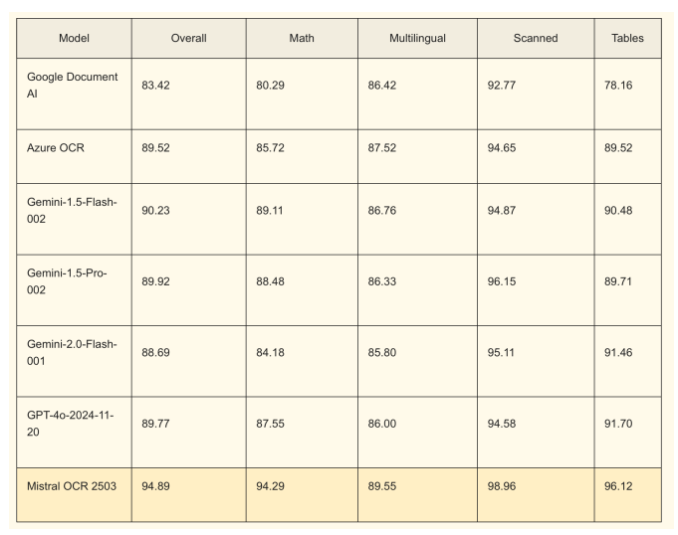
据Mistral称,其OCR API在性能上优于Google、Microsoft和OpenAI的同类产品。该API已通过包含数学表达式(LaTeX格式)、高级布局和表格的复杂文档测试,并在处理非英文文档时表现更佳。此外,由于Mistral OCR专注于单一功能,其处理速度也优于多模态LLM(如GPT-4o)。
Mistral还将Mistral OCR用于其AI助手Le Chat。当用户上传PDF文件时,Le Chat会在后台使用Mistral OCR解析文档内容,然后再进行文本处理。
开发人员和企业可以将Mistral OCR与检索增强生成(RAG)系统结合使用,将多模态文档作为LLM的输入。例如,律师事务所可以利用该技术快速浏览大量法律文档。
















